
Une indisponibilité réseau, même de quelques minutes, peut rapidement se transformer en pertes de chiffre d’affaires, retards de production, appels clients non traités, ou impossibilité d’accéder aux applications métiers. Pour une entreprise réseau informatique, l’objectif n’est pas seulement “que ça marche”, c’est de garantir une disponibilité mesurable, résiliente face aux incidents et adaptée aux contraintes locales (climat, énergie, connectivité, délais logistiques) en Martinique, Guadeloupe et Guyane.
Ce guide rassemble 8 bonnes pratiques concrètes pour améliorer l’uptime de votre réseau, réduire les interruptions et mieux maîtriser vos risques.
Avant de parler technique : définir “disponibilité” avec les bons indicateurs
La disponibilité ne se résume pas à un ressenti. Pour piloter correctement votre réseau, alignez les équipes (direction, métiers, IT, prestataire) sur quelques indicateurs simples.
| Indicateur | À quoi il sert | Exemple concret |
|---|---|---|
| SLA (Service Level Agreement) | Engagement contractuel de disponibilité | “99,9% mensuel sur le réseau du siège” |
| SLO (Service Level Objective) | Objectif interne plus opérationnel | “Wi‑Fi bureaux disponible 8h-18h avec latence cible” |
| MTTR (Mean Time To Repair) | Temps moyen de rétablissement | “Rétabli en 45 minutes en moyenne” |
| RTO (Recovery Time Objective) | Délai max acceptable pour reprendre | “Internet de secours actif en 15 min” |
| RPO (Recovery Point Objective) | Perte de données acceptable (plutôt PRA/PCA) | “Perte max 4 heures de données” |
Même sans viser une complexité excessive, formaliser ces notions vous aide à arbitrer les investissements (redondance, supervision 24/7, lien de secours) selon l’impact métier réel.
8 bonnes pratiques de disponibilité pour un réseau d’entreprise
1) Concevoir une architecture redondante (sans surdimensionner)
La disponibilité se gagne d’abord sur l’architecture. Le principe est simple : supprimer les points uniques de défaillance (single point of failure), là où une panne coupe tout.
Dans la pratique, les axes les plus rentables sont souvent :
- Deux équipements critiques quand l’activité le justifie (pare-feu, cœur de réseau, switch principal).
- Alimentation sécurisée (onduleurs dimensionnés, protection électrique, circuits séparés si possible).
- Redondance logique (liens agrégés, bascule, haute disponibilité) plutôt que “acheter plus gros”.
Aux Antilles-Guyane, cette approche est particulièrement importante à cause des aléas électriques, des épisodes climatiques et des délais d’approvisionnement matériels. L’objectif n’est pas le “zéro panne” (illusoire), mais une panne qui n’arrête pas l’entreprise.
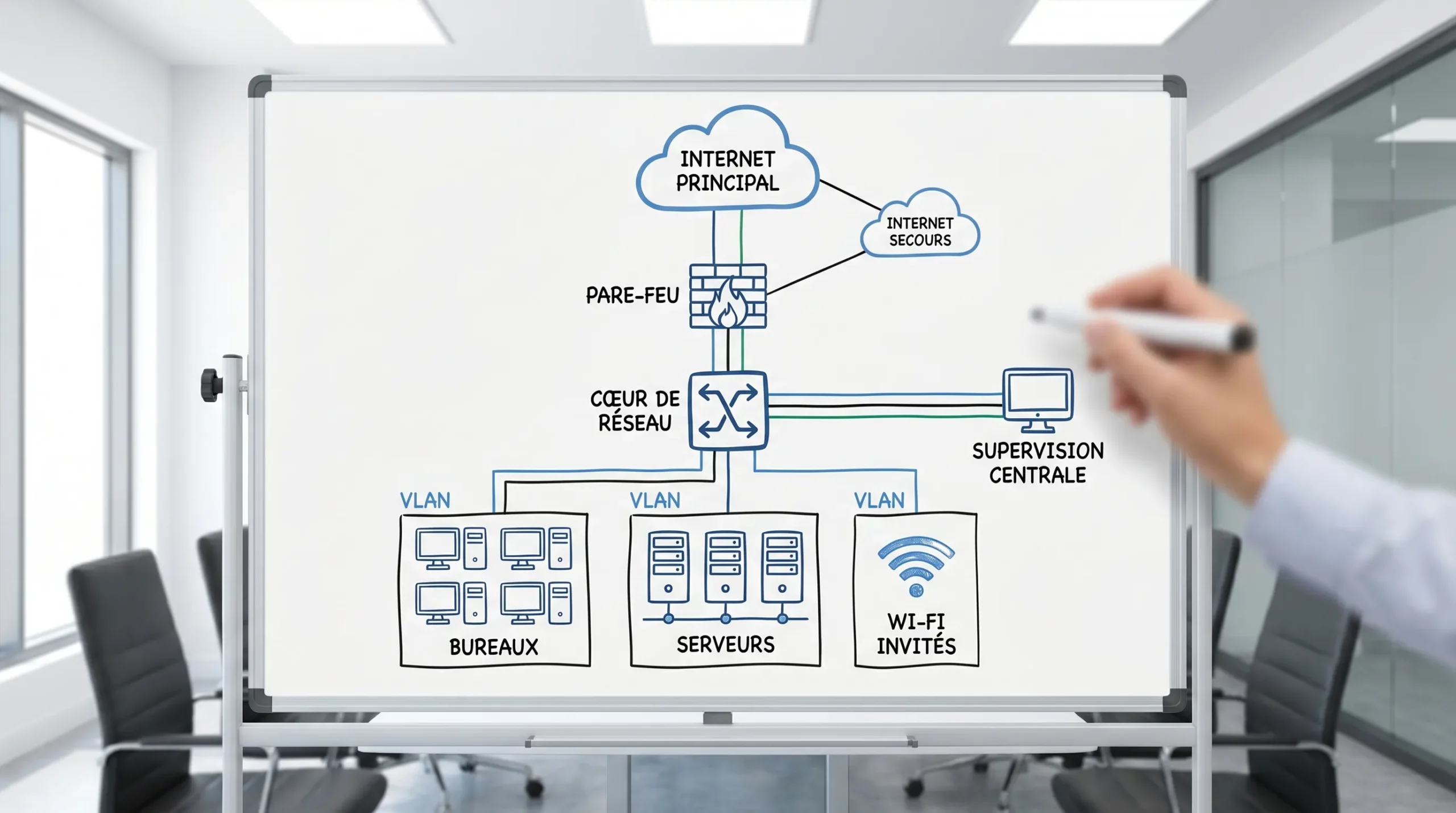
2) Séparer le réseau en zones (segmentation) pour éviter l’effet domino
Un réseau plat, où tout parle à tout, est fragile. Un incident (boucle, tempête de broadcast, mauvaise configuration, poste infecté) peut se propager et provoquer une indisponibilité générale.
La segmentation améliore la disponibilité, car elle limite la zone impactée. On la met en place via des VLAN et des règles de filtrage adaptées :
- Zone utilisateurs
- Zone serveurs
- Zone téléphonie/VoIP
- Zone invités (Wi‑Fi visiteurs)
- Zone équipements (imprimantes, IoT, vidéosurveillance)
Côté cybersécurité, cette approche est également recommandée par les autorités, notamment dans les bonnes pratiques d’hygiène de l’ANSSI.
3) Mettre une supervision proactive (et l’adosser à une astreinte)
La différence entre un réseau “qui tombe” et un réseau “qui tient” se joue souvent sur la détection. Une supervision efficace repère les signaux faibles avant la coupure : erreurs d’interface, saturation de lien, hausse de latence, CPU anormal, température, pertes de paquets.
Pour gagner en disponibilité, visez une supervision qui couvre :
- État (up/down) mais aussi performance (latence, jitter, bande passante)
- Équipements (switches, routeurs, pare-feu, contrôleurs Wi‑Fi)
- Services critiques (DNS, DHCP, VPN, accès applicatifs)
La supervision seule ne suffit pas si personne n’agit. Elle doit être couplée à un processus d’escalade clair (qui est appelé, en combien de temps, avec quel niveau de criticité). C’est typiquement l’intérêt d’un support structuré et, selon le besoin, d’un support 24/7.
4) Standardiser et maîtriser les changements (change management)
Beaucoup d’indisponibilités proviennent… des changements. Une mise à jour faite au mauvais moment, une règle pare-feu modifiée sans validation, un switch remplacé sans config conforme.
Adopter un minimum de gouvernance change tout :
- Fenêtres de maintenance planifiées (même courtes)
- Sauvegarde des configurations avant changement
- Relecture (pair review) sur les modifications sensibles
- Procédure de retour arrière (rollback) prête et testée
Référence utile : les bonnes pratiques ITIL sur la gestion des changements sont largement utilisées pour réduire les incidents liés aux modifications (voir l’introduction sur le site ITIL).
5) Gérer les mises à jour avec une stratégie “disponibilité d’abord”
Ne pas patcher expose à des failles, mais patcher sans méthode peut couper la production. La bonne pratique consiste à organiser les mises à jour comme un processus récurrent et sécurisé.
Approche recommandée :
- Prioriser : équipements exposés (VPN, pare-feu), puis services critiques
- Tester quand c’est possible (pré-production ou pilote)
- Mettre à jour hors heures sensibles, avec supervision renforcée
- Documenter versions et dépendances
En environnement PME, une stratégie réaliste (et régulière) est souvent plus efficace qu’un “grand ménage” annuel qui génère du risque.
6) Sécuriser DNS/DHCP et éviter les pannes invisibles
Quand Internet “ne marche plus”, ce n’est pas toujours le lien. Une panne DNS ou DHCP peut immobiliser l’entreprise entière : postes qui ne reçoivent plus d’adresse IP, noms de domaines non résolus, applications inaccessibles.
Bonnes pratiques simples :
- Redonder les serveurs DNS/DHCP (ou prévoir un service de secours)
- Surveiller les baux DHCP, l’épuisement de pool et les conflits
- Documenter les dépendances (contrôleur de domaine, équipements réseau, Wi‑Fi)
C’est un point souvent sous-estimé, mais très rentable en disponibilité.
7) Prévoir une connectivité de secours adaptée à vos usages
Dans de nombreuses entreprises, la connectivité Internet est devenue un “bus applicatif” : cloud, messagerie, ERP, accès distant, sauvegardes. Une coupure peut tout arrêter.
Une stratégie de disponibilité pragmatique consiste à définir :
- Les usages à maintenir en mode dégradé (mail, accès applicatifs, téléphonie, caisse)
- Le type de lien de secours pertinent (second opérateur, routeur 4G/5G, faisceau local)
- Le mode de bascule (automatique si possible, sinon procédure rapide et testée)
Le point clé est le test. Un lien de secours non testé est souvent inutilisable le jour J (NAT, VPN, priorisation, débit réel, couverture mobile, etc.).
8) Documenter, cartographier, et entraîner la réponse incident
La documentation est une pratique de disponibilité, pas un luxe. En cas d’incident, elle réduit le MTTR (temps de rétablissement) et évite les erreurs sous pression.
Minimum vital :
- Plan d’adressage, VLAN, schéma des interconnexions
- Inventaire des équipements, versions, configs sauvegardées
- Contacts opérateurs, accès, escalades
- Procédures : redémarrage maîtrisé, bascule, restauration
Ajoutez un entraînement périodique sous forme d’exercice : “coupure Internet”, “panne firewall”, “Wi‑Fi indisponible”. Même 30 minutes une fois par trimestre peuvent faire une énorme différence.
Pour structurer la réponse aux incidents, la publication NIST SP 800-61 (Computer Security Incident Handling Guide) fournit un cadre utile, y compris pour les incidents qui affectent la disponibilité.
Synthèse : les 8 pratiques et leur gain attendu
| Bonne pratique | Gain principal | Effet concret sur la disponibilité |
|---|---|---|
| Architecture redondante | Résilience | Moins de coupures “totales” |
| Segmentation réseau | Confinement | Incident limité à une zone |
| Supervision proactive + astreinte | Détection rapide | MTTR réduit |
| Change management | Moins d’incidents | Changements plus sûrs |
| Stratégie de patch | Stabilité + sécurité | Moins de pannes après MAJ |
| DNS/DHCP robustes | Continuité “invisible” | Moins de pannes globales |
| Connectivité de secours testée | Continuité métier | Reprise rapide en cas de coupure opérateur |
| Documentation + exercices | Rétablissement rapide | Moins d’erreurs, diagnostic accéléré |
Erreurs fréquentes qui font chuter la disponibilité (et comment les éviter)
Sans multiplier les outils, certains pièges reviennent souvent dans les PME :
- Tout miser sur un seul “gros” équipement : si le cœur tombe, tout tombe. La redondance ciblée est plus efficace.
- Empiler les solutions sans règles : Wi‑Fi ajouté au fil du temps, switches hétérogènes, configs divergentes, puis pannes difficiles à diagnostiquer.
- Ne pas tester les scénarios (bascule Internet, restauration, reboot contrôlé) : le jour où cela arrive, personne n’a le mode opératoire.
FAQ
Quelles sont les causes les plus fréquentes d’indisponibilité réseau en entreprise ? La plupart des pannes viennent d’une combinaison de changements non maîtrisés, d’équipements non redondés, de saturations (lien, CPU, Wi‑Fi), ou de services DNS/DHCP défaillants. Les coupures opérateur et les incidents électriques restent aussi majeurs.
Faut-il forcément une supervision 24/7 pour garantir la disponibilité ? Pas toujours. Tout dépend de vos horaires d’activité, de vos dépendances au cloud et du coût d’une interruption. En revanche, une supervision proactive avec un processus d’escalade clair est fortement recommandée.
Quel est un bon objectif de disponibilité pour une PME ? Il n’existe pas de chiffre unique. Commencez par cartographier les services critiques et le coût d’arrêt. Certaines PME visent 99,5% sur le Wi‑Fi interne et 99,9% sur l’accès aux applications critiques, mais l’objectif doit être aligné sur vos contraintes métier et budgétaires.
Un lien Internet de secours en 4G/5G suffit-il ? Il peut suffire pour maintenir l’essentiel (messagerie, applications légères, accès distant), mais il faut vérifier la couverture, le débit réel, la stabilité et surtout tester la bascule. Certaines activités (VoIP, transferts lourds) peuvent nécessiter un second lien filaire.
En quoi la segmentation améliore-t-elle la disponibilité, au-delà de la sécurité ? Elle empêche qu’un incident local (boucle réseau, poste infecté, équipement instable) ne se propage. On réduit ainsi l’impact et on rétablit plus vite, car le diagnostic est plus ciblé.
Améliorer votre disponibilité réseau aux Antilles-Guyane avec AITEC
Si vous souhaitez sécuriser votre réseau et réduire concrètement les interruptions, l’approche la plus efficace consiste souvent à démarrer par un état des lieux (architecture, risques, dépendances, procédures) puis à dérouler un plan d’amélioration réaliste.
AITEC accompagne les entreprises en Martinique, Guadeloupe et Guyane avec des services d’infogérance, de réseaux et connectivité, de cloud et de cybersécurité, avec un support 24/7 selon les besoins. Vous pouvez en savoir plus sur l’accompagnement AITEC et demander un premier échange via le site : aitec-antilles.com.


